

Benchmark GPGPU



Questo pannello benchmark, che può essere lanciato da Strumenti | GPGPU Benchmark, offre una serie di benchmark OpenCL GPGPU. Questi sono progettati per misurare le prestazioni di elaborazione GPGPU utilizzando vari carichi di lavoro OpenCL. Ogni singolo benchmark può essere eseguito su un massimo di 16 GPU, comprese le GPU AMD, Intel e NVIDIA, o una combinazione di queste. Naturalmente, le configurazioni CrossFire e SLI, nonché sia dGPU che APU sono completamente supportate. Attualmente, esiste solo un supporto preliminare per le configurazioni HSA. In pratica, qualsiasi dispositivo informatico elencato come GPU tra i dispositivi OpenCL sarà sottoposto a benchmark.
Gli attuali benchmark OpenCL non sono ottimizzati per nessuna architettura GPU. Invece, il modulo AIDA64 OpenCL si basa sul compilatore OpenCL che ottimizza il kernel OpenCL per funzionare al meglio sull'hardware sottostante. I kernel OpenCL utilizzati per questi benchmark vengono compilati in tempo reale, utilizzando il driver OpenCL della GPU. Per questo motivo, si consiglia sempre di avere tutti i driver video (Catalyst, ForceWare, HD Graphics, ecc.) aggiornati all'ultima versione. Per la compilazione vengono passate le seguenti opzioni del compilatore OpenCL: -cl-fast-relaxed-math -cl-mad-enable.
A scopo di confronto, il pannello GPGPU benchmark offre anche misurazioni del processore. Tuttavia, i benchmark del processore non utilizzano OpenCL, ma sono scritti in codice macchina nativo x86/x64, utilizzando le estensioni del set di istruzioni disponibili come SSE, AVX, AVX2, FMA e XOP. Questi benchmark del processore sono molto simili ai vecchi benchmark del processore e FPU AIDA64, ma questa volta misurano le massime prestazioni di calcolo (FLOPS, IOPS). I benchmark del processore sono molto multi-thread e sono ottimizzati per ciascuna architettura del processore introdotta dal primo Pentium.
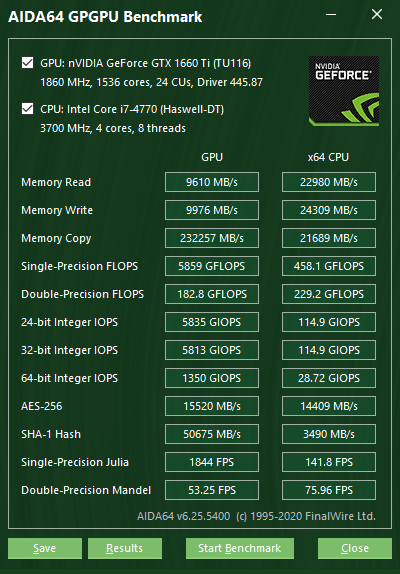
Attualmente sono disponibili i seguenti benchmark test:
Memoria in lettura
Misura la larghezza di banda tra il dispositivo GPU ed il processore, misurando efficacemente le prestazioni che la GPU può copiare i dati dalla memoria del proprio dispositivo alla memoria di sistema. Si chiama anche larghezza di banda da host a dispositivo. Il benchmark del processore misura la larghezza di banda di lettura della memoria, ovvero la velocità con cui il processore può leggere i dati dalla memoria di sistema.
Memoria in scrittura
Misura la larghezza di banda tra il processore ed il dispositivo GPU, misurando efficacemente le prestazioni che la GPU può copiare i dati dalla memoria di sistema nella memoria del proprio dispositivo.Si chiama anche larghezza di banda da host a dispositivo. Il benchmark del processore misura la larghezza di banda di scrittura della memoria, ovvero la velocità con cui il processore può scrivere i dati nella memoria di sistema.
Copia in memoria
Misura le prestazioni della memoria del dispositivo della GPU, misurando efficacemente le prestazioni che la GPU può copiare i dati dalla memoria del proprio dispositivo in un'altra posizione nella stessa memoria del dispositivo. Si chiama anche larghezza di banda da dispositivo a dispositivo. Il benchmark del processore misura la larghezza di banda della copia della memoria, ovvero la velocità con cui il processore può spostare i dati nella memoria di sistema da un luogo all'altro.
FLOPS a precisione singola
Misura le prestazioni MAD (Multiply-Addition) della GPU, altrimenti note come FLOPS (Floating-Point Operations Per Second), con dati a virgola mobile a precisione singola (32 bit, "float").
FLOPS a precisione doppia
Misura le prestazioni MAD (Multiply-Addition) della GPU, altrimenti note come FLOPS (Floating-Point Operations Per Second), con dati a virgola mobile a doppia precisione (64 bit, "doppio"). Non tutte le GPU supportano operazioni in virgola mobile a doppia precisione. Ad esempio, gli attuali dispositivi di grafica desktop e mobili Intel supportano solo operazioni a virgola mobile a precisione singola.
IOPS interi 24-bit
Misura le prestazioni MAD (Multiply-Addition) della GPU, altrimenti nota come IOPS (Integer Operations Per Second), con dati interi a 24 bit ("int24"). Questo tipo di dati speciale è definito in OpenCL, dato che molte GPU sono in grado di eseguire operazioni int24 nelle loro unità a virgola mobile, aumentando efficacemente le prestazioni intere di un fattore da 3 a 5 rispetto alle operazioni su interi a 32 bit.
IOPS interi 32-bit
Misura le prestazioni MAD (Multiply-Addition) della GPU, altrimenti nota come IOPS (Integer Operations Per Second), con dati interi a 32 bit ("int").
IOPS interi 64-bit
Misura le prestazioni MAD (Multiply-Addition) della GPU, altrimenti nota come IOPS (Integer Operations Per Second), con dati interi a 64 bit ("long"). La maggior parte delle GPU non dispone di risorse di esecuzione dedicate per operazioni con numeri interi a 64 bit. Tali dispositivi emulano operazioni intere a 64 bit sulle loro unità di esecuzione intere a 32 bit. In questi casi, le prestazioni dei numeri interi a 64 bit possono essere molto basse.
AES-256
Possiamo utilizzare questo benchmark GPGPU basato su OpenCL per misurare le prestazioni di crittografia AES-256 dei moderni processori grafici e APU.
SHA-1
Possiamo utilizzare questo benchmark GPGPU basato su OpenCL per misurare le prestazioni di hashing SHA-1 dei moderni processori grafici ed APU.
Julia a precisione singola
Misura le prestazioni in virgola mobile a precisione singola (32 bit, "float") attraverso il calcolo di diversi fotogrammi del popolare frattale di "Julia".
Mandel a precisione doppia
Misura le prestazioni in virgola mobile a doppia precisione (64 bit, "doppia") attraverso il calcolo di diversi fotogrammi del famoso frattale "Mandelbrot". Non tutte le GPU supportano operazioni in virgola mobile a doppia precisione. Ad esempio, gli attuali desktop Intel ed i dispositivi grafici mobili supportano solo operazioni a virgola mobile a precisione singola.
Interfaccia utente
Puoi utilizzare le caselle di controllo per selezionare un dispositivo GPU o il processore per i benchmark. Lo stato della casella di controllo del processore verrà memorizzato dopo la chiusura del pannello.
Puoi avviare i benchmark per i dispositivi selezionati facendo clic sul pulsante "Avvia benchmark". Se vuoi eseguire tutti i benchmark, ma solo sulle GPU, devi fare doppio clic sull'etichetta della colonna GPU. Se desideri solo eseguire i benchmark di lettura della memoria sia sulle GPU che sulla CPU, devi fare doppio clic sull'etichetta di lettura della memoria. Se desideri eseguire il benchmark Memory Read solo sulle GPU, devi fare doppio clic sulla cella in cui apparirà il risultato del benchmark richiesto una volta completato il benchmark.
I benchmark vengono eseguiti contemporaneamente su tutte le GPU selezionate, utilizzando più thread e più contesti OpenCL, ciascuno con una singola coda di comandi. I benchmark del processore, tuttavia, vengono avviati solo quando i benchmark della GPU sono stati completati. Al momento non è possibile eseguire contemporaneamente i benchmark di GPU e processore.
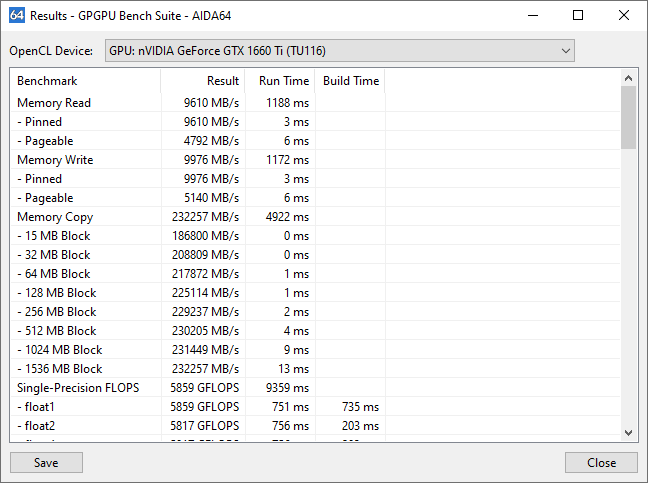
Se sono presenti più GPU nel sistema, la prima colonna dei risultati visualizzerà un punteggio aggregato per tutte le GPU. I risultati delle singole GPU vengono combinati (sommati) e l'etichetta della colonna apparirà es.: “4 GPUs”. Se vuoi controllare i singoli risultati, puoi controllare solo una GPU o fare clic sul pulsante Risultati per aprire la finestra dei risultati.
Se hai due dispositivi GPU e disabiliti il test processore deselezionando la relativa casella di controllo, il pannello passerà alla modalità dual-GPU in cui la prima colonna viene utilizzata per visualizzare i risultati per GPU1 e la seconda per GPU2. Se vuoi vedere le prestazioni combinate di entrambe le GPU, seleziona nuovamente la casella di controllo processore dopo che il benchmark è stato completato e l'interfaccia tornerà alla visualizzazione predefinita.