

Misurazione della performance



AIDA64 include anche numerosi benchmark che rilevano le prestazioni dei singoli componenti dei computer. Si tratta di benchmark sintetici ovvero possono essere utilizzati per rilevare la performance massima teorica degli hardware. I test che misurano la performance del processore (CPU) e dell’unità di calcolo in virgola mobile (FPU) si basano sul motore di misurazione della performance multithread di AIDA64 che, nelle versioni v3.20 e successive, è in grado di gestire in contemporanea 640 thread di programma e anche 10 gruppi di processori. Il motore supporta completamente anche i sistemi multi-core e con tecnologia HyperThreading.
Velocità delle cache e dei dispositivi di memorizzazione
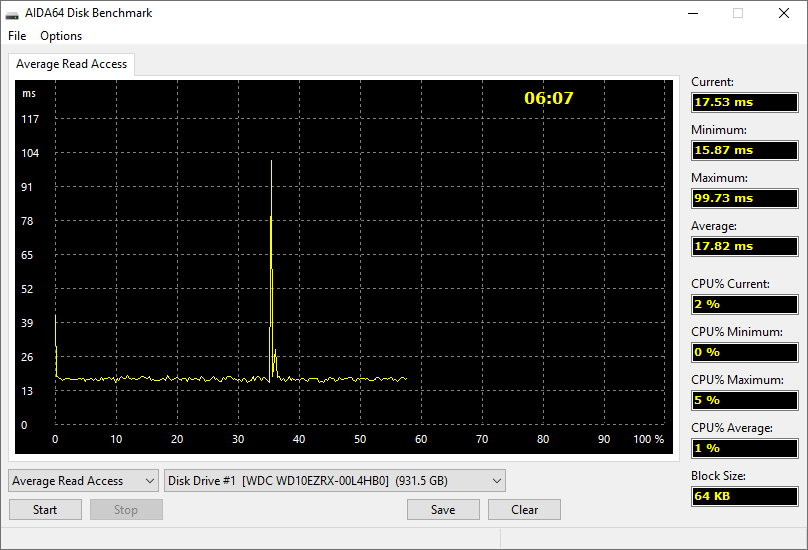
AIDA64 include un modulo apposito per misurare insieme la velocità e la latenza di scrittura, lettura e copia della memoria e della cache così come per verificare la velocità di trasmissione dati dei dispositivi di memorizzazione. Quest’ultimo permette di testare la performance non soltanto di dischi rigidi ma anche di blocchi RAID, unità ottiche, unità Zip e memoria flash.
Misurazione della performance della GPGPU
Questo modulo di benchmark, che può essere raggiunto cliccando su Strumenti | Misurazione della velocità della GPGPU, include dei benchmark GPGPU basati su OpenCL. La performance di calcolo della GPGPU del computer viene misurato con diversi compiti OpenCL. Ogni singola misurazione può essere lanciata in contemporanea addirittura su 16 GPU, che si tratti di chip grafici AMD, Intel oppure NVIDIA oppure della loro combinazione. Naturalmente il modulo supporta completamente anche le configurazioni CrossFire e SLI, nonché le dGPU e le APU. Attualmente per il dispositivo HSA è disponibile solamente un supporto preliminare. In pratica il modulo misura la performance di tutti i dispositivi che risultano come GPU tra i dispositivi OpenCL.
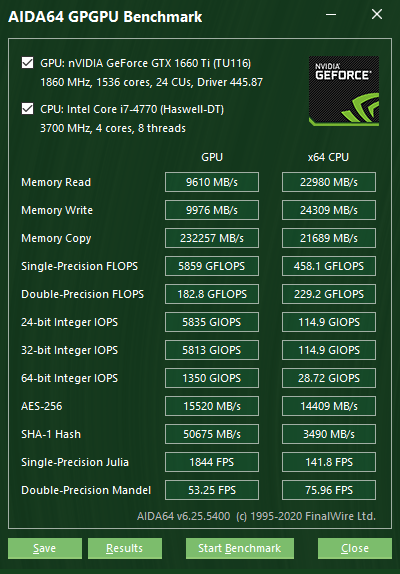
Il software, oltre a questi benchmark complessivi ha anche algoritmi di benchmarking mirati che si trovano nella categoria Velocità del menu laterale. Grazie all’enorme database di riferimento, i risultati delle singole misurazioni possono essere anche confrontate con i risultati di altre configurazioni. In AIDA64 sono disponibili i seguenti mini benchmark:
Misurazione della performance della memoria
Per le operazioni di memoria (lettura, scrittura, copia), i benchmark misurano la massima velocità di trasferimento dati disponibile quando si esegue una data operazione. Questi sono scritti in linguaggio assembly e sono ottimizzati per i popolari processori AMD, Intel e VIA utilizzando le estensioni dei set di istruzioni x86/x64, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX e AVX2.
Il benchmark di latenza della memoria misura il tempo necessario al processore per ricevere dati dalla memoria. La latenza quindi è il tempo necessario ai dati per entrare nel registro intero del processore dal momento in cui viene emessa l'istruzione di lettura.
CPU Queen

Questo benchmark intero misura l'efficienza della logica di stima dei rami del processore e l'impatto delle stime errate. Il test cerca una soluzione al classico "problema delle otto regine" su una scacchiera 10x10. In teoria, a parità di clock, un processore con un nastro più corto e una "penalità" più bassa per la stima errata dei rami avrà prestazioni migliori in questa misurazione. Ad esempio, un processore Intel Pentium 4 basato su un core Northwood (con HyperThreading disattivato) avrà un punteggio più alto della sua controparte con core Prescott, perché il primo usa un nastro a 20 stadi e il secondo un nastro a 31 stadi. La misurazione della CPU Queen utilizza ottimizzazioni MMX, SSE2 e SSE3 intere.
CPU PhotoWorxx

Questo benchmark esegue operazioni comunemente utilizzate nell’elaborazione di immagini digitali, esegui le seguenti operazioni su un’immagine RGB di dimensioni estremamente grandi:
- caricare l'immagine con pixel di diversi colori scelti a caso
- ruotare di 90 gradi in senso antiorario
- ruotare di 180 gradi
- differenza
- conversione dello spazio colore (usato per esempio nella conversione JPEG)
Questo benchmark mette sotto carico l’unità aritmetica intera SIMD del processore e il sottosistema delle memorie. Il test CPU PhotoWorxx utilizza le estensioni del set di istruzioni x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2 e XOP su CPU compatibili e supporta le architetture NUMA, HyperThreading, sistema multiprocessore simmetrico (SMP) e processore multi-core Processor (CMP).
CPU ZLib
Questo benchmark intero misura la performance del processore e del sottosistema delle memorie utilizzando la libreria di compressione ZLib. Il test CPU ZLib utilizza esclusivamente le istruzioni x86 e supporta le architetture HyperThreading, sistema multiprocessore simmetrico (SMP) e processore multi-core Processor (CMP).
CPU AES
Questo benchmark misura la performance della CPU utilizzando il processo di crittografia dei dati AES (Advanced Encryption Standard). Nella crittografia AES è uno standard di cifratura a chiave simmetrica, che viene utilizzato da numerosi programmi di compressione (tra cui 7z, RAR, WinZip) e diverse soluzioni di crittografia del disco (BitLocker, FileVault, TrueCrypt). Il test CPU AES utilizza i set di istruzioni x86, MMX e SSE4.1 sui processori compatibili e funziona con l'accelerazione hardware sui processori VIA C3, C7, Nano e QuadCore che supportano il VIA PadLock Security Engine, così come sulle CPU Intel che supportano AES-NI. La misurazione supporta le architetture HyperThreading, sistema multiprocessore simmetrico (SMP) e processore multi-core Processor (CMP).
CPU Hash
Questo benchmark misura la performance della CPU utilizzando l'algoritmo di hash SHA1. Il codice è scritto in linguaggio assembly ed è ottimizzato per i popolari processori AMD, Intel e VIA utilizzando le estensioni del set di istruzioni MMX, MMX+/SSE, SSE2, SSE3, AVX, AVX2, XOP, BMI e BMI2. Il test viene eseguito con accelerazione hardware su processori VIA C3, C7, Nano e QuadCore che supportano il VIA PadLock Security Engine.
FPU VP8
questo benchmark misura la performance della compressione video del processore utilizzando il codec video Google VP8 (WebM) versione 1.1.0 (http://www.webmproject.org/). Il test codifica i fotogrammi video alla risoluzione di 1280x720 pixel (HD ready) in modalità single-step a 8192 kbps di velocità di trasferimento e alle impostazioni di qualità più alte. I fotogrammi vengono generati dal modulo frattale giuliano della FPU. Il test sfrutta le estensioni dei set di istruzioni MMX, SSE2, SSE3 e SSE4.1 sui processori compatibili e supporta le architetture HyperThreading, sistema multiprocessore simmetrico (SMP) e processore multi-core Processor (CMP).
FPU Julia

Questo benchmark misura la performance di calcolo in virgola mobile a singola precisione (o 32 bit) calcolando un frattale giuliano su diversi fotogrammi. Il test è stato scritto in linguaggio assembly ed è stato ottimizzato al massimo per i popolari processori AMD, Intel e VIA utilizzando le estensioni dei set di istruzioni x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA e FMA4. La misurazione supporta le architetture HyperThreading, sistema multiprocessore simmetrico (SMP) e processore multi-core Processor (CMP).
FPU Mandel

Questo benchmark misura la performance di calcolo in virgola mobile a doppia precisione (o 64 bit) calcolando un frattale Mandelbrot su diversi fotogrammi. Il test è stato scritto in linguaggio assembly ed è stato ottimizzato al massimo per i popolari processori AMD, Intel e VIA utilizzando le estensioni dei set di istruzioni x87, SSE2, AVX, AVX2, FMA e FMA4. La misurazione supporta le architetture HyperThreading, sistema multiprocessore simmetrico (SMP) e processore multi-core Processor (CMP).
FPU SinJulia

Questo benchmark misura la performance di calcolo in virgola mobile a precisione estesa (o 80 bit) calcolando un frattale giuliano modificato su un singolo fotogramma. Il test è stato scritto in linguaggio assembly ed è stato ottimizzato al massimo per i popolari processori AMD, Intel e VIA utilizzando istruzioni trigonometriche ed esponenziali x87. La misurazione supporta le architetture HyperThreading, sistema multiprocessore simmetrico (SMP) e processore multi-core Processor (CMP).